多情境下的交通视频多目标跟踪算法
曾哲妮
编者按:清华“挑战杯”科展诞生于1983年,每年举办一次,以集中展示学生课外科技创新成果。本届“挑战杯”科展作为清华109周年校庆活动的一部分,首次尝试在线上举办;新雅书院有三件作品入展,分别是陈伟浩同学的“BiTipText双手指尖盲打”,郑智、崔琢宜、张皓烨同学的“基于强化学习的裂脑机器人研究”,曾哲妮同学的“多情境下的交通视频多目标追踪系统”。
摘要
多目标跟踪,即Multiple Object Tracking(MOT),指给定一个图像序列,希望找到图像序列中某些运动物体,并将不同帧的运动物体进行匹配识别。在实际应用场景中,自动辨识道路视频中的车流通行情况与交通违章行为需要强有力的多目标跟踪算法支持。本作品在目前最流行的MOT开源算法deep SORT上进行改进,有下述两个主要贡献:1. 考虑到车辆视频低帧高速的特性,减弱坐标绝对位置的约束作用,尝试搭建运动模型进行位置预测;2. 提出将pipeline参数在各交通情境下进行自适应调整的想法,显著提升算法作用效果。
普适性改进
a)前处理。检测器返回的bounding box通常存在不少冗余,对于置信度不高的检测对象,可以考虑直接忽略。另外,reid特征提取的可靠性在图片太小、太不清晰时也大打折扣,故筛除面积太小的检测框。
b) 轨迹合并时间差限定。只用reid阈值进行相似程度判断并规定bbox移动速度合理是不够的,可能存在把不同时间出现的相似车辆轨迹连起来的情况。我们规定在每一个traj的“交错点”时间差不能超过2秒。
c) 匹配策略。目前直接取当前traj前向检测框的平均特征与待匹配框进行计算(或计算平均距离,在该codebase上效果差异不明显)。考虑到时间越近的框与当前结果应越相似,可以尝试引入时间衰减权重项。另外,在进入匈牙利算法之间可以将分数足够高的 pair 预订匹配。
d) 轨迹检测框quality判别。其一是通过逻辑筛选特征突变或判定遮挡框;其二是通过框大小、图片模糊因子等从CNN中得到quality分数。
车辆运动假设模型
行人的运动状况复杂多变,很多方案中使用卡尔曼滤波器解决,但效果上也没有特别突出。车辆的运动相对固定而简单不少,但移动相对画幅而言更加明显,故不能简单地视之为线性运动模型。尝试使用二次拟合方案得到 estimated position 来计算IoU,会更有参考价值;同时也能代替速度阈值筛选,能纳入更多快车。
对于一条轨迹向前回溯3秒找到所有检测框。为筛选位置置信度高的框,分别对检测框长和宽做线性拟合。若实际长宽与回归值的比超出容忍范围,则不纳入后续计算。对剩余检测框取至多10个在x与y方向分别进行二次拟合。我们得到了对检测框的长、宽以及中心位置的回归函数,可以代入当前帧求解。为避免结果出现明显不符合常理的偏移趋势,我们规定:w与h能过小。若求解结果为负说明该条轨迹应已消失;正常车辆长宽比应在既定范围内,若形状偏差太大应向中庸作出调整;不能越过二次函数顶点,最近一帧检测框与预测结果应在对称轴同侧。这并不表示车辆实际轨迹不能出现反向弯,而是避免预测框回退到其余车辆上的情况发生。
绘制预测框的位置并与实际检测框位置进行比对,发现该模型对于动态和静态车辆的预测效果都比较良好(橙色为预测框,其余颜色为被匹配的检测框):

图1 车辆运动预测结果(a)

图2 车辆运动预测结果(b)
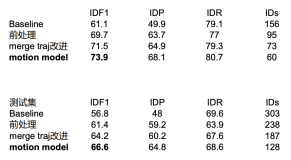
图3 普适改进与运动模型在业务视频上的测试结果
参数自适应调整
我们为MOT中的pipeline参数调整提出了一个新颖的自评测参数。现有的评测参数全部要求在有ground truth的情况下进行,故而在实际应用的多变环境下失效。而我们的参数反映了假设轨迹的内部特征,不需gt标注即可评测跟踪质量。
从观察经验中得到,好的跟踪轨迹结果应尽可能长且轨迹同时尽可能多,以确保所有符合规定的运动物体都被纳入考虑且不出现不合理的断裂或串联。在此前提下,我们认为相同轨迹所有帧图像特征应尽可能相似而不同轨迹间特征应尽可能相异。基于该假设可以得到,理想轨迹的自差和互差应呈单峰分布,而多峰则往往暗示着轨迹错误。
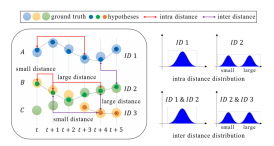
图4 轨迹分布假设
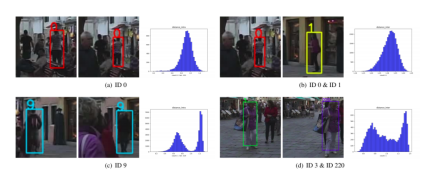
图5 轨迹分布假设在MOT16集上的验证
从该现象出发,利用2-class高斯混合模型进行轨迹帧特征欧式距离分布的拟合,并根据峰间距判断其质量。由于基于x该方法在MOT16 Challenge等经典数据集上取得了良好的表现。这也是在整个MOT社群中首次提出的自评测方法。
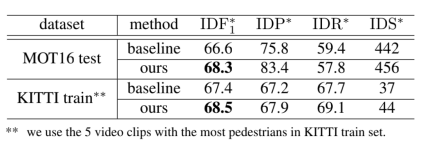
图6 自适应算法在MOT16与KITTI数据集上的测试结果




 您当前所在位置:
您当前所在位置:
